Replacing WebRTC
The long path to use something else for real-time media.
tl;dr
If you primarily use WebRTC for…
- real-time media: it will take a while to replace WebRTC; we’re working on it.
- data channels: WebTransport is amazing and actually works.
- peer-to-peer: you’re stuck with WebRTC for the forseeable future.
Disclaimer
I spent almost two years building/optimizing a partial WebRTC stack @ Twitch using pion. Our use-case was quite custom and we ultimately scrapped it, but your millage may vary.
Why WebRTC?
Google released WebRTC in 2011 as a way of fixing a very specific problem:
How do we build Google Meet?
Back then, the web was a very different place. Flash was the only way to do live media and it was a mess. HTML5 video was primarily for pre-recorded content. It personally took me until 2015 to write a HTML5 player for Twitch using MSE, and we’re still talking 5+ seconds of latency on a good day.
Transmitting video over the internet in real-time is hard.
You need a tight coupling between the video encoding and the network to avoid any form of queuing, which adds latency. This effectively rules out TCP and forces you to use UDP. But now you also need a video encoder/decoder that can deal with packet loss without spewing artifacts everywhere.

Source. Example of Artifacts caused by packet loss.
Google (correctly) determined that it would be impossible to solve these problems piecewise with new web standards. The approach instead was to create libwebrtc, the defacto WebRTC implementation that still ships with all browsers. It does everything, from networking to video encoding/decoding to data transfer, and it does it remarkably well. It’s actually quite a feat of software engineering, especially the part where Google managed to convince Apple/Mozilla to embed a full media/networking stack into their browsers.
My favorite part about WebRTC is that it manages to leverage existing standards. WebRTC is not really a protocol, but rather a collection of protocols: ICE, STUN, TURN, DTLS, RTP/RTCP, SRTP, SCTP, SDP, mDNS, etc. Throw a Javascript API on top of these and you have WebRTC.
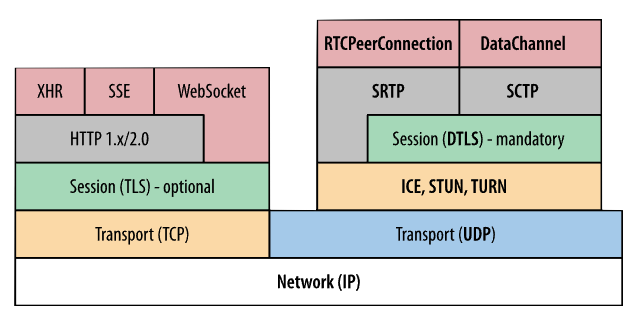
Why not WebRTC?
I wouldn’t be writing this blog post if WebRTC was perfect. The core issue is that WebRTC is not a protocol; it’s a monolith.
WebRTC does a lot of things, let’s break down it down piece by piece:
- Media: a full capture/encoding/networking/rendering pipeline.
- Data: reliable/unreliable messages.
- P2P: peer-to-peer connectability.
- SFU: a relay that selectively forwards media.
Media
The WebRTC media stack is designed for conferencing and does an amazing job at it. The problems start when you try to use it for anything else.
My final project at Twitch was to reduce latency by replacing HLS with WebRTC for delivery. This seems like a no-brainer at first, but it quickly turned into death by a thousand cuts. The biggest issue was that the user experience was just terrible. Twitch doesn’t need the same aggressive latency as Google Meet, but WebRTC is hard-coded to compromise on quality.
In general, it’s quite difficult to customize WebRTC outside of a few configurable modes. It’s a black box that you turn on, and if it works it works. And if it doesn’t work, then you have to deal with the pain that is forking libwebrtc… or just hope Google fixes it for you.
The protocol has some wiggle room and I really enjoyed my time tinkering with pion. But you’re ultimately bound by the browser implementation, unless you don’t need web support, in which case you don’t need WebRTC.
Data
WebRTC also has a data channel API, which is particularly useful because until recently, it’s been the only way to send/receive “unreliable” messages from a browser. In fact, many companies use WebRTC data channels to avoid the WebRTC media stack (ex. Zoom).
I went down this path too, attempting to send each video frame as an unreliable message, but it didn’t work due to fundamental flaws with SCTP. I won’t go into the detail in this post, but I eventually hacked “datagram” support into SCTP by breaking frames into unreliable messages below the MTU size.
Finally! UDP* in the browser, but at what cost:
- a convoluted handshake that takes at least 10 (!) round trips.
- 2x the packets, because libsctp immediately ACKs every “datagram”.
- a custom SCTP implementation, which means the browser can’t send “datagrams”.
Oof.
P2P
The best and worst part about WebRTC is that it supports peer-to-peer.
The ICE handshake is extremely complicated, even from the application’s point of view. Without going into detail, there’s an explosion of permutations that you need to handle based on the network topology. Some networks block P2P (ex. symmetric NATs) while others outright block UDP, forcing you to use a TURN server a non-insignificant amount of time.
Most conferencing solutions are client-server anyway, relying on their own private network instead of public transit (aka a CDN). However the server is still forced to perform the complicated ICE handshake which has major architecture ramifications, but I’ll save that for another blog post.
Note that there are rumblings of P2P WebTransport and P2P QUIC, but I wouldn’t hold my breath.
SFU
Last but not least, WebRTC scales using SFUs (Selective Forwarding Units).
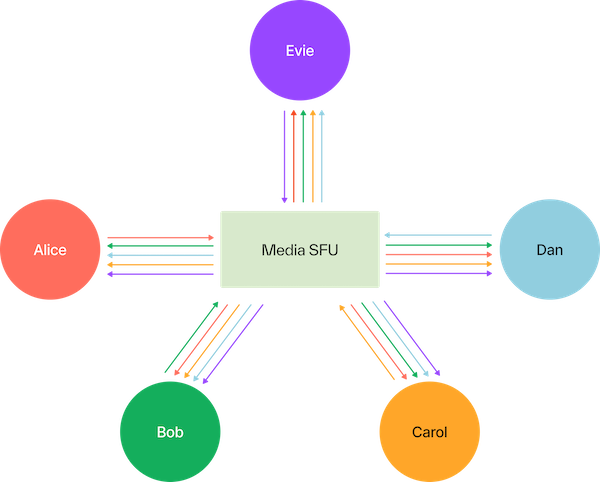
Source. Participants send to a central server, rather than directly to each other.
The problem with SFUs is subtle: they’re custom.
It requires a lot of business logic to determine where to forward packets. A single server like that diagram won’t scale, nor will all of the participants be located in the same geo. Each SFU needs to be made aware of the network topology and the location of each participant somehow.
Additionally, a good SFU will avoid dropping packets based on dependencies, otherwise you waste bandwidth on undecodable packets. Unfortunately, determining this requires parsing each RTP packet on a per-codec basis. For example, here’s a h.264 depacketizer for libwebrtc.
But the biggest issue at Twitch was that SFUs share very little in common with CDNs. One team is optimizing WebRTC, another team is optimizing HTTP, and they’re not talking to each other.
This is why HLS/DASH uses HTTP instead: economies of scale
Replacing WebRTC
Okay enough ranting about what’s wrong, let’s fix it.
First off, WebRTC is not going anywhere. It does a fantastic job at what it was designed for: conferencing. It will take a long time before anything will reach feature/latency parity with WebRTC.
Before you can replace WebRTC, you need WebSupport. Fortunately, we now have WebCodecs and WebTransport.
WebCodecs
WebCodecs is a new API for encoding/decoding media in the browser. It’s remarkably simple:
- Capture input via canvas or a media device.
- VideoEncoder: Input raw frames, output encoded frames.
- Transfer those frames somehow. (ex. WebTransport)
- VideoDecoder: Input encoded frames, output raw frames.
- Render output via canvas or just marvel at the pixel data.
The catch is that the application is responsible for all timing. That means you need to choose when to render each frame via requestAnimationFrame. In fact, you need to choose when to render each audio sample via AudioWorklet.
The upside is that now your web application gets full control of how to render media. It’s now possible to implement WebRTC-like behavior, like temporarily freezing video and desyncing A/V.
Check caniuse for current browser support.
WebTransport
WebTransport is a new API for transmitting data over the network. Think of it like WebSockets, but with a few key differences:
- QUIC not TCP.
- Reliable streams that are delivered in order.
- Semi-reliable streams by closing a stream (with an error code) to drop the tail.
- Unreliable datagrams that may be dropped during congestion.
QUIC has too many benefits to enumerate, but some highlights:
- Fully encrypted
- Congestion controlled (even datagrams)
- Independent streams (no head-of-line blocking)
- 1-RTT handshake
- Multiplexed over a single UDP port
- Transparent network migration (ex. switching from Wifi to LTE)
- Used for HTTP/3
That last one is surprisingly important: WebTransport will share all of the optimizations that HTTP/3 receives. A HTTP/3 server can simultaneously serve multiple WebTransport sessions and HTTP requests over the same connection.
Check caniuse for current browser support. Use my Rust library for servers and native clients!
But how?
Okay, so we have WebCodecs and WebTransport, but are they actually useful?
I alluded to the secret behind latency earlier: avoiding queues. Queuing can occur at any point in the media pipeline.
| Capture/Encode | Send/Receive | Decode/Render |
|---|---|---|
| —> | —> | —> |
Let’s start with the easy one. WebCodecs allows you to avoid queuing almost entirely.
| Capture/Encode | Send/Receive | Decode/Render |
|---|---|---|
| WebCodecs | ? | WebCodecs |
The tricky part is the bit in the middle, the network. It’s not as simple as throwing your hands into the air and proclaiming “UDP has no queues!”
The Internet of Queues
The internet is a series of tubes. You put packets in one end and they eventually come out of the other end, kinda. This section will get an entire blog post in the future, but until then, let’s over-simplify things.
Every packet you send will fight with other packets on the internet.
- If routers have sufficient throughput, packets arrive on time.
- If routers have limited throughput, packets will be queued.
- If those queues are full, packets will be dropped.
There can be random packet loss, but 99% of the time we care about loss due to queuing. Note that even datagrams may be queued by the network; a firehose of packets is never the answer.
Detecting Queuing
The goal of congestion control is to detect queuing and back off.
Different congestion control algorithms use different signals to detect queuing. This is a gross oversimplification of a topic with an immense amount of research, but here’s a rough breakdown:
| Signal | Description | Latency | Examples |
|---|---|---|---|
| Packet Loss | Wait until the queue is full and packets are dropped. | High | Reno, CUBIC |
| ACK Delay | Indirectly measure the queue size via ACK RTT. | Medium | BBR, COPA |
| Packet Delay | Indirectly measure the queue size via packet RTT. | Low | GCC, SCReAM |
| ECN | Get told by the router to back off. | None* | L4S |
There’s no single “best” congestion control algorithm; it depends on your use-case, network, and target latency. But this is one area where WebRTC has an advantage thanks to transport-wide-cc.
Reducing Bitrate
Once you detect queuing, the application needs to send fewer bytes.
In some situations we can just reduce the encoder bitrate, however:
- This only applies to future frames.
- We don’t want one viewer to degrade the experience for all.
- It’s too expensive to encode on a per-viewer basis.
So basically, we have to drop encoded media in response to congestion.
This is the fundamental problem with TCP. Once you queue data on a TCP socket, it can’t be undone without closing the connection. You can’t put the toothpaste back in the tube.

Source. You earned a meme for making it this far.
However, there are actually quite a few ways of dropping media with WebTransport:
- Use datagrams and choose which packets to transmit. (like WebRTC)
- Use QUIC streams and close them to stop transmissions. (like RUSH)
- Use QUIC streams and prioritize them. (like Warp)
I’m biased because I made the 3rd one. WebTransport’s sendOrder can be used to instruct the QUIC stack what should be sent during congestion. But that deserves an entire blog post on its own.
Replacing WebRTC
But to actually replace WebRTC, we need a standard. Anybody can make their own UDP-based protocol (and they do), using this new web tech (and they will).
What sets Media over QUIC apart is that we’re doing it through the IETF, the same organization that standardized WebRTC… and virtually every internet protocol.
It’s going to take years.
It’s going to take a lot of idiots like myself who want to replace WebRTC.
It’s going to take a lot of companies who are willing to bet on a new standard.
And there are major flaws with both WebCodecs and WebTransport that still need to be addressed before we’ll ever reach WebRTC parity. To name a few:
- We need better congestion control in browsers.
- We need something like transport-wide-cc in QUIC: like this proposal
- We need echo cancellation in WebAudio, which might be possible?
- We may need FEC in QUIC: like this proposal
- We may need more encoding options, like non-reference frames or SVC.
- Oh yeah and full browser support: WebCodecs - WebTransport
So yeah…
Written by @kixelated. Hit me up on Discord if you want to help!
Tune in for next week’s episode: Replacing HLS/DASH and then Replacing RTMP.
