published 11/17/2024
The MoQ Onion
Today we slice the onion. The most critical, and least documented, thing to understand is the layering behind MoQ.
Without further blabbering, from the bottom to top:
- QUIC: The network layer
- Web Transport: Browser compatibility
- MoQ Transfork: Media-like pub/sub.
- MoQ Karp: A media playlist and container.
- Ur App: Your application.
This layering is the most crucial concept behind MoQ. We explicitly want to avoid building yet another monolithic and inflexible media protocol built directly on top of UDP. Sorry SRT, you’re not invited to this party.
This guide will also help explain the IETF drafts. Of course I decided to fork them, but the high level concepts are still very similar. Just gotta rename a few things:
Yes, I used unoriginal names on purpose. Your mental model should thank me.
QUIC
If you’ve used TCP before (and you have), you’ll know that it’s fully reliable and ordered. It’s a FIFO over the internet. But the internet is full of rough seas. Step outside and you’ll encounter a swirling typhoon in the form of a 🌀 loading 🌀 animation. Sometimes we don’t want to wait for everything; sometimes we want to skip.
This is not a new problem. There have been many attempts to fix the head-of-line blocking with HTTP:
-
With HTTP/1, browsers would utilize multiple TCP connections to each host. However, each connection involves a relatively expensive TCP/TLS handshake and these connections would compete for resources.
-
With HTTP/2, browsers would utilize a single, shared TCP connection to each host. However, despite the illusion of independent requests and a complex prioritization scheme, it all gets interleaved into a single pipe.
-
With HTTP/3, TCP was replaced with QUIC. Head-of-line blocking is no more*. What? How?

QUIC combines the two approaches by sharing some state (like HTTP/2) while providing independent streams (like HTTP/1). Each HTTP request is a QUIC stream that can be created, delivered, and closed in parallel with minimal overhead. All of the encryption, congestion control, and flow control is shared at the connection level.
But hang on, why not build on top of UDP like scores of other, live media protocols? It’s pretty simple actually:
- QUIC is wicked smart: check out my QUIC POWERS post for more info.
- QUIC is available in the browser.
- QUIC benefits from economies of scale (many implementations).
The point of MoQ is to fully utilize QUIC’s features to deliver live media. We’re not reinventing the wheel nor are we checking a box for marketing reasons.
Web Transport
I just said QUIC was created for HTTP/3… so why not use HTTP/3? That’s QUIC right?
Well you can totally use HTTP/3 to implement something like MoQ, but the HTTP semantics add more hoops to jump through.
My main gripe with HTTP is that it’s not designed for live content. The client has to know what content to request, which is kind of a problem when that content doesn’t exist yet. You end up relying on everybody’s favorite hacks: polling and long-polling. Also, the client/server model means that contribution (client->server) and distribution (server->client) must be handled separately.
Somebody else should and will make “Media over HTTP/3” (hit up my DMs @pantos).
I’m interested in WebTransport instead. It’s a browser API that exposes QUIC browser applications, similar to how WebSockets exposes TCP*. The connection-oriented nature makes it significantly easier to push media without the HTTP request/response song and dance. There’s not much else to say, it’s basically the same thing as QUIC.
…except that the underlying implementation is gross. A WebTransport session shares a QUIC connection with HTTP/3 requests and potentially other WebTransport sessions (spec). This pooling feature is responsible for a ton of headaches but the IETF went ahead and standardized it anyway (despite my best efforts).
So we use WebTransport for WebSupport. That’s why this layer exists; we’re forced to use it. Choose a WebTransport library (like mine!) and pretend it’s just QUIC.
WebRTC
Before we get into the good stuff (my protocol ofc), it’s best to learn from the failures of other protocols.
One of the biggest headaches with WebRTC is scale. WebRTC supports peer-to-peer communication, but this requires the broadcaster sends a copy of each packet to all viewers. Obviously this falls down as the number of participants grows, so the usual solution is to have all participants send to a central server instead: a Selective Forwarding Unit (SFU). Our server can then use the power of DATA CENTERS and PEERING to fan the content out to viewers.
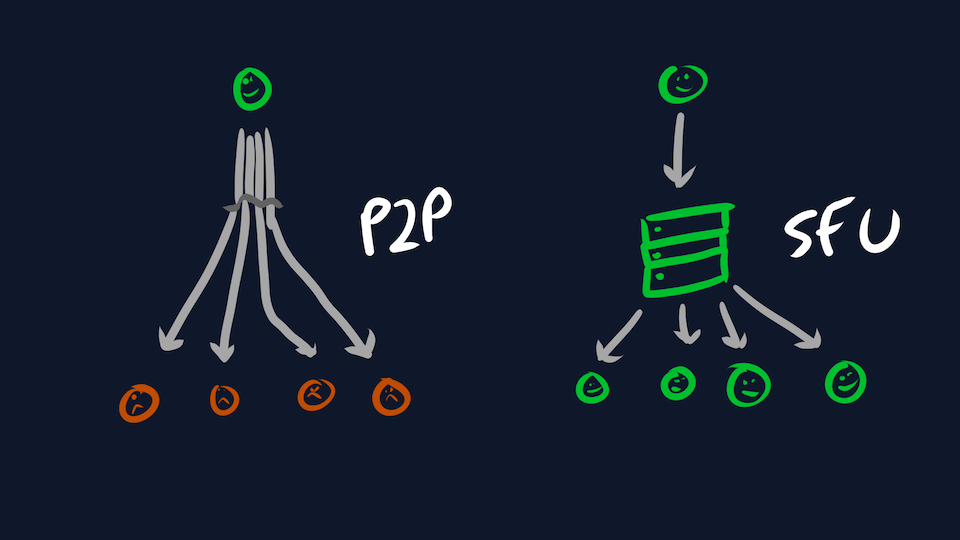
Unfortunately, WebRTC does a poor job of facilitating this. The network transport (RTP) is tightly coupled to the application (also RTP). Without going into too much detail, an SFU has to pretend to be another participant, performing hacks along the way to stay compliant with the standard. Ultimately, every major service makes a custom SFU implementation to handle the quirks of their application. If you want a longer rant, check out my Replacing WebRTC.
My bold claim: WebRTC doesn’t scale because it’s not generic.
For those with a HTTP background, this is something we take for granted. Want to scale your application? Throw nginx in front of it. Still doesn’t scale? Throw a CDN in front of it. Still doesn’t scale? Throw more money at it.
But HTTP is a pain for live content. It’s totally possible, but like mentioned in the previous section, you’re jumping through hoops. What we really want are the great HTTP cache/fanout semantics but with the ability to PUSH.
MoqTransfork
So here were are. MoQ Transfork is an ambitious attempt to learn from the succesess of HTTP and the aforementioned failures of WebRTC. But you know, for live content and not hyper-text.
The idea is that generic relays and CDNs implement Transfork but not the media layer. The Transfork headers contain enough information to facilitate optimal caching and fanout even in congested scenarios. The application can encode whatever it wants into the payload; it doesn’t need to be media and it could even be encrypted.
Here’s the general flow:
- A client establishes a Session to a server.
- Both sides can Announce available tracks by name.
- Both sides can Subscribe to a live tracks by name with a priority.
- A Track is broken into groups, each delivered independently with a priority.
- A Group consists of ordered frames, delivered reliably unless cancelled.
- A Frame is a sized chunk of data.
The most crucial concept is how live media is mapped to Transfork. This is main reason why I forked the IETF draft; it needed to be done right.
You see, video encoding is a form of delta encoding. To over-simplify, a video stream involves a periodic I-frame (static image) followed by P-frames (delta). If we lose a frame, then our diffs get out sync and there’s ugly artifacts until the next I-frame. You’ve probably seen this before; it looks like you’re tripping balls.
And yet we also need a plan for congestion. We don’t want to ⏸️ pause ⏸️ and 🌀 buffer 🌀 during a conference call so we need to drop something. This is a contentious subject but I think there’s only one option: skip frames until the next I-frame. In order to do that, we need to split up the live stream and deliver it in pieces.
These are known as a Group of Pictures aka a GoP aka a HLS/DASH segment aka a Transfork Group. Unlike the IETF draft, Transfork maps a GoP directly to a QUIC Stream which provides reliability and ordering. There’s no need for a reassembly buffer in our application; QUIC will make sure that every frame is delivered and in the correct order.
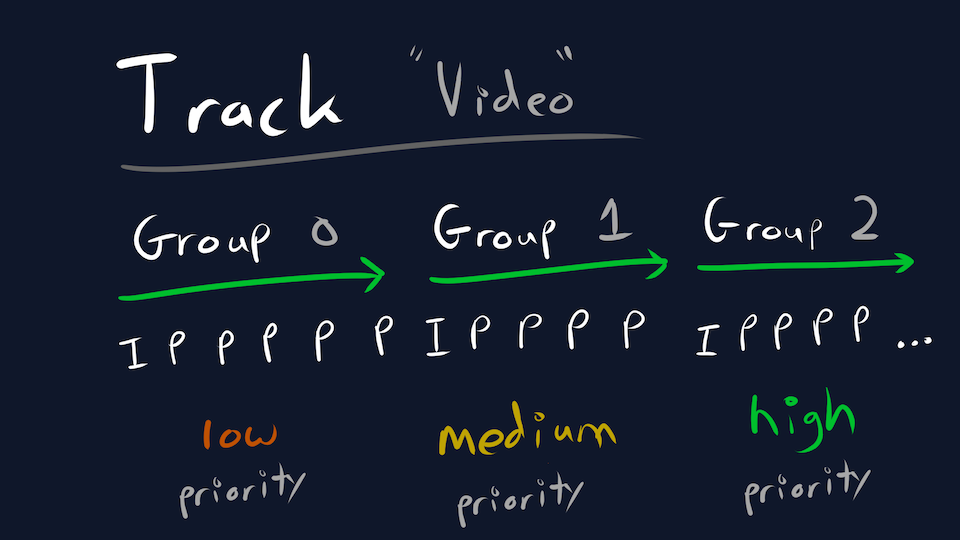
And crucially, QUIC streams can be prioritized. We tell the QUIC layer to transmit packets according to a (deterministic) priority when bandwidth is limited. The most important groups are delivered (ex. newer audio) while the least important groups will be starved (ex. older video). And if any group is starved for too long, either side can explicitly cancel it and move on.
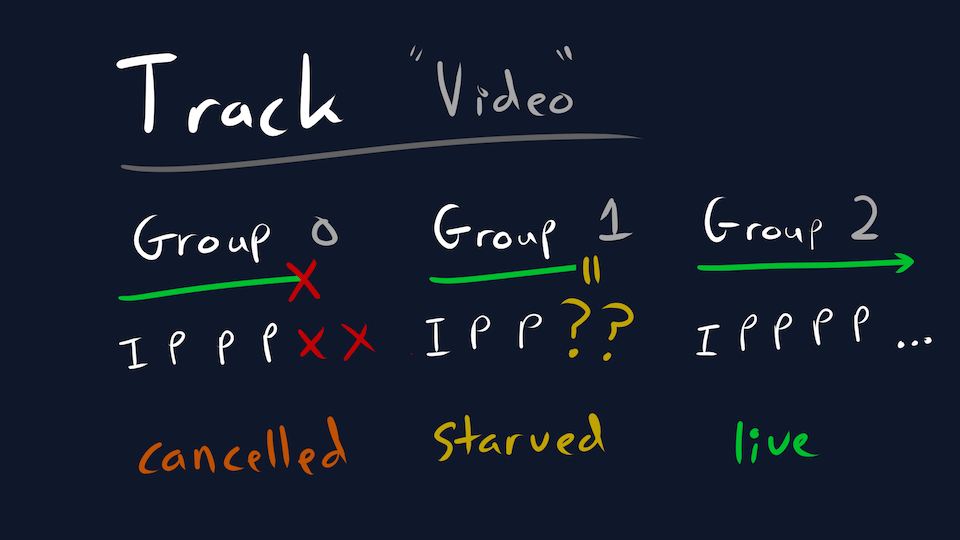
And just like that, we can achieve latency close to WebRTC levels with limited complexity. We still need to improve QUIC’s congestion control to reach parity with WebRTC, but that’s a problem for another day.
But what about other latency targets? Well this is why I very specifically said we starve streams, not drop them. If a viewer is willing to accept higher latency to avoid stalls, they do so by having a larger buffer. A larger buffer means more time for network starvation to recover, and thus group starvation to recover. We only cancel a QUIC stream after the viewer decides to skip ahead, if that every happens (ex. VOD).
Prioritization is a superset of dropping. We don’t need no stinking UDP.
One last thing rant.
I think the IETF is overfixated on the “generic” angle.
MoqTransport has become a solution in search of a problem (more use-cases).
Unfortunately, the core live media use-case has been neglected in favor of convoluted abstractions and useless features.
I think this stems from a misunderstanding of the layering. Transfork SHOULD NOT be thought of as a generic HTTP replacement. Instead, Transfork is a clear layer in the sand: it’s the bare minimum that a live media client/server need to support.
The server doesn’t care about the media encoding which is why it’s delegated to a higher layer (spoilers). It’s a side-benefit that the transport is generic, not the explicit goal. I think Transfork could become less generic, for example by adding timestamps to each frame, but only if this information would be useful for the server.
Karp
Okay okay, so it’s finally time for the big reveal: the M in MoQ. Karp is a layer on top of MoqTransfork that actually does the Media stuff. It’s also the simplest. Wowee.

Karp is modeled after the WebCodecs API. It’s just enough metadata to initialize a decoder and render a frame. It’s not a on-disk media container like MP4 or MKV, instead it’s optimized for low overhead live streaming.
Karp consists of:
- A catalog: A JSON blob describing the tracks.
- A container: A simple header in front of the codec data.
The Catalog is delivered over a Transfork track, commonly named catalog.json.
It contains available tracks within a broadcast and metadata about them.
The viewer subscribes to this catalog, determines if a track is desired/decodable, and then subscribes to individual media tracks.
Let’s just dive into an example because it explains itself:
{
"video": [{
// Transfork information
"track": {
"name": "480p",
"priority": 2
},
// The codec in use.
"codec": "avc1.64001f",
// The resolution of the video
"resolution": {
"width": 1280,
"height": 720
},
// The maximum bitrate (3Mb/s)
"bitrate": 3000000
// etc
}],
}Of course, the catalog can contain multiple tracks, audio and video but also alternative renditions.
For example, two tracks could have the same content but different settings, like 480p vs 1080p.
A viewer can choose which one it wants based on the indicated bitrate and resolution.
The concept is similar to a HLS/DASH playlist or SDP monstrosity, but it’s a strongly-typed JSON schema. But the unlike those crummy afformentioned formats, this catalog can be updated; it’s a live track itself! Viewers will Subscribe to the catalog and receive updates via Groups or delta Frames. Just like that, you can add or remove tracks on the fly.
The Container is even less interesting. Originally, Warp used fMP4. This is great for a company like Twitch who already uses fMP4 (aka CMAF) for HLS/DASH delivery.
Unfortunately, this container is not designed for live streaming. You can minimize latency by fragmenting (the f in fMP4) at each frame but this involves ~100 bytes of overhead. This is nearly the size of OPUS audio packet; doubling our network usage for audio-only streams is unacceptable.
So we’re not using fMP4, we’re using our own container. It consists of:
- A 1-8 byte presentation timestamp.
- A payload.
That’s it. That’s it!
Obviously we’ll need more functionality in the future so expect to see updates on Karp. For example, keying information used for encryption or DRM (not the same thing lul). But the goal is to keep it simple.
UrApp
MoQ can provide video and audio delivery. You’re on your own for the rest. Fly free little developer.
Of course there are libraries to help. Nobody is expecting you to write your own QUIC, Transfork, or Karp implementation. Likewise I expect there will be other layers on top of MoqTransfork, for example a chat protocol.
But ultimately, you’re responsible for your application. It shouldn’t be generic, it’s yours!
But neither should MoQ be one-size-fits-all. You will inevitably need to extend MoQ to fit your needs. I don’t want that to involve clicking the “Feature Request” button.
But how do you extend MoQ? Well of course it depends on the layer, perhaps:
- A QUIC extension?
- A WebTransport extension?
- A MoqTransfork extension?
- A MoqTransfork track.
- A MoqKarp extension?
One of those in particular should stick out: you can create arbitrary tracks.
For example, you could create a custom controller or chat track alongside the Karp tracks.
You get all of the benefits of MoqTransfork, like prioritization and caching, without having to reinvent the wheel.
But you do need to figure out how to delta encode your content into Groups and Frames.
For example, the MoQ relays tracks to gossip available broadcasts and routes.
Each node creates a cluster.<node> track and subscribes to all other cluster.* tracks.
The track is just a series of + or - deltas indicating when a broadcast has started or stopped.
Dog fooding to the max.
You too can abuse MoQ to deliver non-media content. Perhaps one day this blog post will be delivered over MoQ too…
Out of Date
MoQ is evolving rapidly. The core concepts are stable but everything else keeps evolving, even the terminology. I’m sure this blog post is already out of date.
Join the conversation and evolve with me, platonically of course.
Written by @kixelated.
![]()